
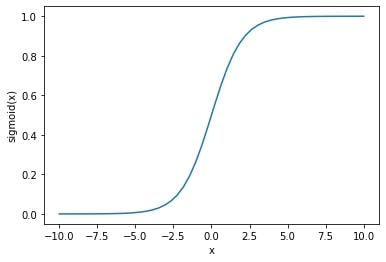
The PyTorch sigmoid function is an element-wise operation that squishes any real number into a range between 0 and 1. This is a very common activation function to use as the last layer of binary classifiers (including logistic regression) because it lets you treat model predictions like probabilities that their outputs are true, i.e. p(y == 1).
Mathematically, the function is 1 / (1 + np.exp(-x)). And plotting it creates a well-known curve:

Similar to other activation functions like softmax, there are two patterns for applying the sigmoid activation function in PyTorch. Which one you choose will depend more on your style preferences than anything else.
Sigmoid Function
The first way to apply the sigmoid operation is with the torch.sigmoid() function:
import torch
torch.manual_seed(1)
x = torch.randn((3, 3, 3))
y = torch.sigmoid(x)
y.min(), y.max()
# Expected output
# (tensor(0.1667), tensor(0.9364))There are a couple things to point out about this function. First, the operation works element-wise so x can have any input dimension you want — the output dimension will be the same. Second, torch.sigmoid() is functionally the same as torch.nn.functional.sigmoid(), which was more common in older versions of PyTorch, but has been deprecated since the 1.0 release.
Sigmoid Class
The second pattern you will sometimes see is instantiating the torch.nn.Sigmoid() class and then using the callable object. This is more common in PyTorch model classes:
class MyModel(torch.nn.Module):
def __init__(self, input_dim):
super().__init__()
self.linear = torch.nn.Linear(input_dim, 1)
self.activation = torch.nn.Sigmoid()
def forward(self, x):
x = self.linear(x)
return self.activation(x)
torch.manual_seed(1)
model = MyModel(4)
x = torch.randn((10, 4))
y = model(x)
y.min(), y.max()
# Expected output
# (tensor(0.2182, grad_fn=<MinBackward1>),
# tensor(0.5587, grad_fn=<MaxBackward1>))The output of this snippet shows that PyTorch is keeping track of gradients for us. But the function and class-based approaches are equivalent — and you’re free to call torch.sigmoid() inside the forward() method if you prefer. If you’re skeptical, then prove it to yourself by copying this snippet and replacing self.activation(x) with torch.sigmoid(x).